DevOps开发与运维的可观测性应用实践
本文目标: 在Golang使用OpenTelemetry Go SDK和API创建和配置 指标 链路 日志这些遥测数据并用OpenTelemetry Collector导出到Prometheus Jaeger和Loki
前言
- 本人目前大三, 更多时候是以Dev身份去写软件.
- 对运维技术细节不太了解, 以一个开发的视角来使用运维技术辅助自己.
- 本文可能有些地方表达不是很合理, 欢迎随时改正.
- 本文倾向于实践, 没有过多理论知识, 本文假设你已经了解Golang, Kubernetes, OpenTelemetry, Prometheus, Jaeger, Loki基本概念
概念
- 可观测性: 不等于监控
- 遥测数据: 分为日志, 链路, 指标
- OpenTelemetry: OpenTelemetry 是OpenCensus 和 OpenTracing 合并的结果。OpenTelemetry(也称为“OTel”)将自己定位为在现代软件世界中处理遥测的与供应商(Prometheus, Jaeger)等后端无关的方法。
- OpenTelemetry API: 负责收集遥测数据以及作为其中一部分的所有数据
- OpenTelemetry SDK: 将这些数据从当前观察到的进程中获取到另一个实体进行分析的原因, 包含常见的Go、Python、Java、Ruby、JavaScript、.NET等语言的SDK实现
- OpenTelemetry Go SDK: OpenTelemetry的Golang的SDK实现
- OpenTelemetry Collector: 收集器, SDK 的部分工作是从正在观察的进程中获取数据,但需要有将此数据发送到的某个位置。这个单独的过程就是我们所说的收集器。收集器的整个工作可以分为三个不同的阶段:
- 接收遥测数据
- 处理遥测数据(可选)
- 导出遥测数据
- OpenTelemetry Exporter: 导出器, 包含
- Prometheus: 收集遥测数据
- Jaeger: 分布式链路追踪
- Loki: 聚合日志
- 追踪(Traces): 跟踪定位到程序上下文出现的问题
- 指标(Metrics): 系统的信息, 例如CPU使用率, 内存使用率, 当前操作系统信息, 路由往返时间片, 用于分析程序的性能
- 日志(Logs): 由开发者编写程序的运行日志, 记录程序的错误消息, 健康状态, OpenTelemetry的Logs日志还在快速迭代开发中, 不稳定
- 自动检测: 不侵入应用源代码的检测方式, 这种方式只能手机应用外的信息, 例如应用的环境(Kubernetes Pod), 应用的健康状态(运行/停止/错误)...
- 手动检测: 嵌入/侵入应用源代码的方式, 自定义需要获取的遥测数据
技术栈
- Kubernetes server: K8S集群服务端
- Golang client & server: Go的服务端��和客户端
- OpenTelemetry client & server: 服务端安装在K8S中用于导出数据等, 客户端创建配置遥测数据等
- Prometheus server: 服务端, 收集遥测数据
- Jaeger server: 服务端, 分布式链路追踪
- Loki server : 聚合日志, 服务端安装
架构
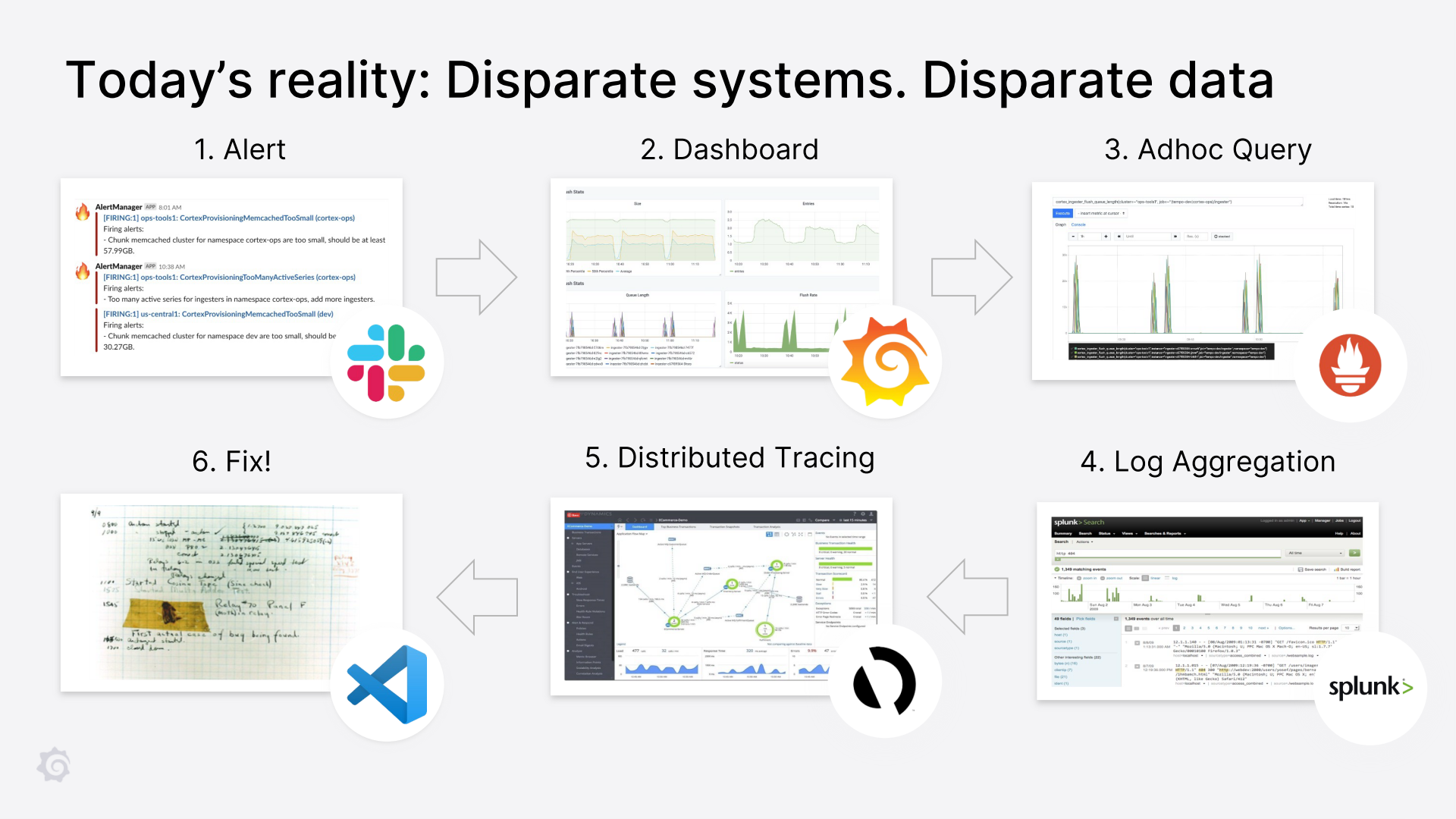
监控流程:
- 问题告警
- 查看Grafana的信息
- 查看Prometheus深入研究问题
- 查看日志
- 链路追踪定位
- 修复问题
引用官方监控告警的流程图: